
")
El passat 13 de març, Andrea Suárez, Fernando Gastón i Marcel Morillas, de la Unitat de Transferència del Coneixement del CRM (KTU), juntament amb Pau Varela i Mariona Fucho, de comunicació i divulgació, van participar a l’EspaiCiència dins del marc del Saló de l’Ensenyament.
Durant l’esdeveniment, van realitzar dos tallers. El primer, dirigit per l’Andrea Suárez, el Fernando Gaston i la Mariona Fucho, va consistir en una sessió pràctica sobre l’ús de la criptografia per a la compressió i transmissió eficient de dades.
Considerant la gran quantitat de dades generades cada minut i els costos associats amb la seva transmissió i emmagatzematge, la KTU, en col·laboració amb l’ALBA sincrotró, participa en el programa DYSEDAS per a la compressió de dades. Segons l’Andrea: “L’objectiu del projecte DYSEDAS és crear un programari per a la compressió d’imatges volumètriques, és a dir, una seqüència de moltes imatges molt semblants entre elles. Hi ha molts marges per a la compressió en aquest cas, atès que hi ha redundància de les dades, i s’estan explorant combinacions d’algorismes coneguts com ara el codi Huffman o el codi Golomb, juntament amb una reordenació o transformació reversibles de les imatges.”
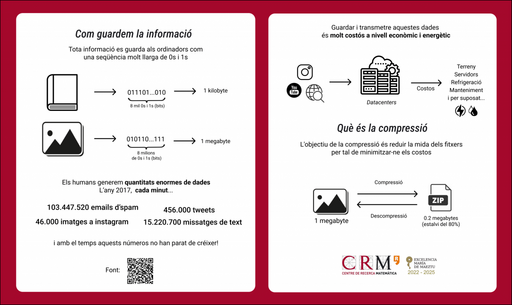
Però, què és exactament la compressió?
La compressió té com a objectiu reduir la grandària dels fitxers per minimitzar-ne els costos.
En el taller, els participants van ser desafiats a codificar una frase de 12 caràcters com “me mira a mi” (incloent-hi els espais) i, utilitzant tres tipus de codis, van investigar si era possible encriptar-los i desencriptar-los. Van observar que un d’aquests codis era molt eficient en la compressió de dades, però no permetia la recuperació de la informació, descobrint així el mètode Huffman.
Què és el mètode Huffman?
El mètode Huffman és un algorisme de compressió de dades que crea codis prefix, assegurant que cap cadena de bits que representa un símbol sigui prefix d’una altra, òptims per a la compressió sense pèrdua d’informació. Va ser desenvolupat per David A. Huffman mentre estudiava a l’MIT i publicat el 1952.
Aquest mètode fa servir una taula de codis de longitud variable basada en la probabilitat o freqüència estimada d’aparició de cada símbol font. Els símbols més comuns són representats amb menys bits, reduint la redundància.
Com funciona el mètode Huffman?
- Analitzar l’entrada: Identifica els símbols únics i calcula les seves freqüències d’aparició.
- Crear nodes inicials: Crea un node per a cada símbol, assignant la seva freqüència com a pes inicial.
- Construir l’arbre Huffman:
- Combina els dos nodes amb menor freqüència per crear un nou node, sumant les seves freqüències.
- Inserir el nou node: Insereix el nou node a l’arbre mantenint l’ordre de freqüència.
- Repetir el procés fins que només quedi un node a l’arbre, que serà l’arrel de l’arbre Huffman.
- Assignar codis: Recorre l’arbre assignant 0 a les branques esquerra i 1 a les branques dreta, registrant el codi binari associat a cada símbol.
- Crear la taula de codis: Utilitza els codis per construir una taula de codis Huffman.
És important assenyalar que tot i ser eficient en la codificació de símbols per separat, el mètode Huffman no sempre és la millor opció comparat amb altres mètodes de compressió com l’arithmetic coding o els sistemes numèrics asimètrics.
Voleu posar-vos a proba?
Proveu a codificar ‘STATISTICS’ i cliqueu-hi a sobre per veure la resposta. Tingueu en compte que la solució no és única.
| Symbol | Probability |
| S | 0.3 |
| T | 0.3 |
| I | 0.2 |
| A | 0.1 |
| C | 0.1 |

El segon taller, a càrrec de l’Andrea Suárez, el Marcel Morillas i en Pau Varela, van explicar en què consisteix la incertesa, específicament, aplicada a models d’intel·ligència artificial.
Per que? Basicament, ens interessa dissenyar sistemes que puguin quantificar la seguretat de les respostes que donen, já que la IA pot ser entrenada amb dadees que no reflecteixin la realitat degut a biaixos de gènere, dades errònies o falta de representació de col·lectius minoritaris.

I… Com puc utilitzar la IA per la ciberseguretat?
El phishing és una estafa en la qual un ciberdelinqüent es fa pasar per algú altre per intentar extreure información sobre la persona afectada maliciosament.
En paraules d’Axel Masó, membre de la KTU, “al projecte LICSAI, la KTU ha elaborat una eina per quantificar la incertesa d’un model de Machine Learning (desenvolupat per I2Cat) que permet predir, donat el comportament virtual d’un individu, quin és el risc que aquest sigui víctima de phishing.”
En el taller, les estudiants havien de llegir uns textos i opinar sobre com de segurs estaven que allò podía ser phishing i, a continuación, entre les dades de tots els participants, van estudiar les gràfiques resultants per entendre el seu significat.

Subscribe for more CRM News
|
|
CRM CommPau Varela & Mariona Fucho
|

Connecting Shapes, Patterns, and Ideas: the Closing Conference on Combinatorial Geometries and Geometric Combinatorics
During five days, the CRM hosted the Closing Conference of the MDM Focused Research Programme on Combinatorial Geometries & Geometric Combinatorics. The event featured plenary talks, contributed sessions, and posters on topics from matroids and polytopes to...

Xavier Ros-Oton among the 65 most cited mathematicians in the world
ICREA professor at the Universitat de Barcelona and CRM affiliated researcher Xavier Ros-Oton appears on Clarivate's Highly Cited Researchers 2025 list, which this year reinstates the mathematics category after two years of exclusion.Citations are a strange way to...

New Horizons for H- and Γ-convergence: From Local to Nonlocal (and viceversa)
The researchers Maicol Caponi, Alessandro Carbotti, and Alberto Maione extended the H- and Γ-convergence theories to the setting of nonlocal linear operators and their corresponding energies. The authors were able to overcome the limitations of classical localization...

Diego Vidaurre joins the CRM through the ATRAE talent programme
Diego Vidaurre has joined the Centre de Recerca Matemàtica through the ATRAE programme, bringing his expertise in modelling spontaneous brain activity across multiple data modalities. His work focuses on understanding how the brain’s intrinsic dynamics shape...

El CRM a la Setmana de la Ciència: una ruta entre dones, formes i pensament
El CRM va participar en la 30a edició de la Setmana de la Ciència amb una ruta guiada que va combinar les biografies de dones matemàtiques amb obres d'art del centre, connectant ciència, història i creació artística.El 12 de novembre, el Centre de Recerca Matemàtica...

Stefano Pedarra Defends his PhD Thesis on the Interaction between Tumour Cells and the Immune System
Stefano Pedarra has completed his PhD at the Centre de Recerca Matemàtica with a thesis exploring how tumour-cell metabolism shapes the immune system’s ability to fight cancer. His work brought mathematics and biology into direct conversation, from building models to...

Els estudiants participants a la prova de preselecció de Bojos per les Matemàtiques visiten el CRM
La prova de preselecció de Bojos per les Matemàtiques va reunir estudiants de tot Catalunya a la UAB i al CRM, amb presentacions a càrrec de Montse Alsina, presidenta de la Societat Catalana de Matemàtiques, Núria Fagella, degana de la Facultat de Matemàtiques i...

Jordi Mompart highlights the role of artificial intelligence in sport at the XIII GEFENOL-DIFENSC Summer School
The XIII GEFENOL-DIFENSC Summer School gathered over thirty researchers from across Europe to explore how statistical physics helps explain complex phenomena in biology, ecology, networks, and social systems. In his closing lecture, Jordi Mompart (UAB) examined how...
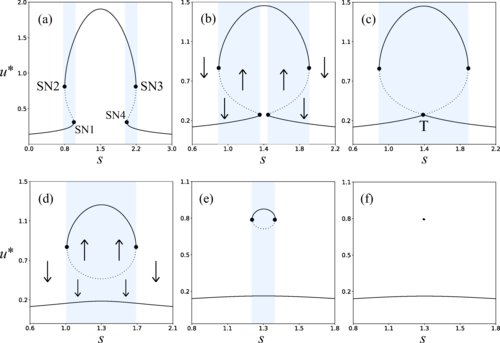
Critical Slowing Down in Genetic Systems: The Impact of Bifurcation Proximity and Noise
An international collaboration including researchers from the Centre de Recerca Matemàtica (CRM) has shown that when several bifurcations occur close to one another, their interaction can dramatically amplify critical slowing down effect - the progressive slowdown of...

Two CRM researchers begin their Marie Skłodowska-Curie fellowships
Gustavo Ferreira and Tássio Naia, CRM postdoctoral researchers and new Marie Skłodowska-Curie fellows. Gustavo Ferreira and Tássio Naia, who joined the CRM in 2023 through the María de Maeztu programme, have started their Marie Skłodowska-Curie postdoctoral...

Matroid Week at CRM: A Collaborative Dive into Combinatorial Geometries
From October 13 to 17, 2025, the CRM hosted Matroid Week, a research school on combinatorial geometries and matroid theory. Courses by Laura Anderson and Geoff Whittle explored intersection properties and structural emergence in matroids. The event fostered deep...

László Lovász receives the 2025 Erasmus Medal in Barcelona
Mathematician László Lovász received the 2025 Erasmus Medal from the Academia Europaea yesterday at the PRBB in Barcelona, where he delivered the lecture “The Beauty of Mathematics”. Renowned for his work in graph theory and discrete mathematics, Lovász has shaped...
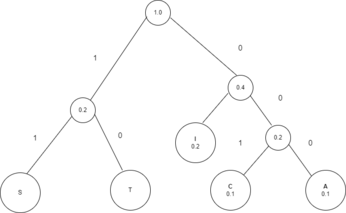
| Symbol | Encoding |
| S | 11 |
| T | 10 |
| I | 01 |
| A | 001 |
| C | 000 |
Resposta encoding ‘Statistics’: 1110000100111100100111
Quant ocupa en bits: 8*10=80 bits.